An expert and a noob sat down to discuss bi-objective optimization. Here´s what ensued.
In Autumn 2022, DALL-E 2 became available for all without having to sign up for a waitlist. Since then, we have witnessed the infinite potential of “generative” AI being pushed out of all tubes (like we say in Finnish) by the media.
At first, I was alarmed by the hype. AI used to be stupid — it could maybe count stuff or correct your grammar. But never write or paint! Those are human things. Meant for humans only.
Since accidentally seeing the music video for “The world is not enough” by Garbage when I was 7, I have had a great fear of robots taking over humanity. Now, this fear seemed to be one step closer to being realized.
Before continuing I do want to add this: I know that just because AI applications are now able to handle vast amounts of data and produce seemingly novel work based on the data, it does not make them intelligent in any way (at least in the traditional sense of the word). Nevertheless, the generative AI hype did make me feel like the age of human enslavement by robots could be looming on the distant horizon. If the revolution of publicly available generative AI was happening now, who knows what was transpiring behind closed lab doors around the world?
I was determined not to stand idle as the AI tsunami would rush over me. I started to research online for texts related to “creative” AI in any shape or form. I read a lot of articles — some of them were well-written, others were less so. But as I kept reading, I noticed myself being steadily steered towards this conclusion:
I would never be able to know what to think of the rise of AI-driven innovation until I knew something about the people who were making it happen.
So, I decided to sit down with one such person. His name is Christoph Jabs, and he is a doctoral researcher in computer science at the University of Helsinki. The research group he is a member of focuses on Constraint Reasoning and Optimization and is led by Professor Matti Järvisalo. The group is currently working on a bi-objective optimization algorithm that they named BiOptSat. You can read more about the algorithm here.
Now, let me be clear — very quickly down the line in the conversation I had with Christoph, he reminded me that what he does is optimization, which is just a small part of what people generally understand AI to mean. Overall, the talk with Christoph made it obvious to me, that whatever I thought I had understood about the subject of AI so far, was either extremely distorted or downright erroneous.
I am very thankful for having had the chance to sit down with Christoph and eventually correct at least some part of my perception of the field.
Author´s note 1: If you are a professional in the field of computer science, you might think that the following conversation adheres to a little bit of unusual logic. It is because I am leading it from the viewpoint of an artist, not an expert in any kind of implementation of AI. No matter who you are, I do hope this interview can shed a little light, if not on anything else, at least on how challenging it is to understand AI as an AI noob.
What kind of AI are you working on in your project?
We are doing what is called optimization. Many people assume that artificial intelligence is the same as machine learning, which is not true. For instance, optimization is not synonymous with machine learning, but you can consider it to be AI if you see AI as something bigger than machine learning. AI is a vague umbrella term for these two terms (and many others that are not discussed here).
Optimization problems have constraints and objectives. An objective tells you what should be achieved, whereas a constraint sets limitations to achieving that goal.
An example of an optimization problem could be weekly timetabling for a school — we have a certain number of subjects that need to be taught, and a certain number of teachers available to teach them, as well as a certain number of students taking the classes. In this case, the constraint could be that a teacher can only teach one class at a time. An objective could be to have the subjects spread out evenly across the timetable for the students to participate in.
BiOptSat is a bi-objective optimization algorithm with many potential applications, but currently, our research group is testing it for one application in machine learning. For this application, BiOptSat is operated as a training algorithm. Most of the applications for BiOptSat are other types of optimization than machine learning, such as the set cover problem, which is a part of the topic of my thesis as well.
Tell me more about machine learning in the context of your project.
In machine learning, there´s always an optimization problem. One approach to solving optimization problems is declarative optimization. Declarative optimization starts with the formulation of a problem in a mathematical language. Multiple different mathematical languages are being used in declarative optimization. BiOptSat uses a kind of language called Boolean logic. In Boolean logic, there are only two values for variables: true and false. They are usually denoted 0=false and 1=true.
Problem formulation for a type of optimization algorithm that uses Boolean logic goes something like this:
1. There´s an informal problem written in natural language. For example: How to make a good timetable for a school with x number of subjects and x number of teachers? A
teacher cannot give two classes at the same time. All subjects need to be spread out evenly across the timetable.
2. An informal problem will be formalized into a Boolean formula. There are many ways of doing this.
3. A question will be presented for the algorithm to answer: Is there an assignment that satisfies the given Boolean formula?
Why did you choose Boolean logic for your algorithm?
It is something we have expertise in already. It is a little bit like being fluent in Spanish, so you make your language research in Spanish.
Some optimization problems are easier to formulate in one mathematical language and some in another. In Boolean logic, the problems are formalized using 3 basic operators: AND, OR, and NOT. You can very easily formulate logical problems in Boolean algebra because most logical problems can be arranged using these words.
When you have formulated a problem in one language, you can still use many algorithms to solve it — although only the algorithms that work for that mathematical language.
Tell me more about BiOptSat.
BiOptSat is a type of exact optimization method. There are two types of optimization algorithms — inexact and exact. Inexact algorithms give a very good, but not necessarily the best solution to a problem. Exact algorithms give exactly the best solution, with a guarantee that it is the best. Traditionally in machine learning, you use inexact algorithms to solve optimization problems. With these, you do not know if there is a better solution available. Exact algorithms are only used for smaller applications where a guarantee of optimality is crucial — and even there, the scalability of exact algorithms is still an issue.
Simply put, machine learning works like this: you have a training process (algorithm 1) that produces a machine learning model (algorithm 2). This model, algorithm 2, is then used in a practical application. A practical application can be anything from a classifier to a predictor.
For example, BiOptSat can be used to produce an algorithm that will evaluate if a picture is a dog or a cat. The goal for algorithm 2 in this case is to tell the right species in each picture among many pictures of dogs and cats with as little margin of error and as quickly, as possible.
I want to emphasize that BiOptSat cannot be directly used in real-life applications. Instead, it works as a building block for them. In machine learning specifically, BiOptSat can be used to create other algorithms called models, making it a training algorithm in this instance. Despite the practical example I gave, the goal for our research group is not to create real-life applications for BiOptSat but to make it as effective as possible for any potential use. Simply put, we have one goal for BiOptSat — for it to be fast in whatever it does.
We evaluate BiOptSat with the help of any suitable data we find; there´s a lot of free data available to use for research purposes. To produce algorithms, BiOptSat utilizes the training data in a process called bi-objective optimization.
Can you elaborate on the concept of the training algorithm a bit more?
While large machine-learning models have millions of parameters, the training algorithm that produces them does not. That is the beauty of them — as a human, you only must tune a few parameters in the training algorithm, and the millions of parameters in the model are automatically tuned by the training process. The model (algorithm 2) the exact training algorithm (algorithm 1) produces is like a black box for its creators, which means they do not know how exactly it produces its results. Machine learning models like these can be found dealing with large amounts of data. These models produce stuff like the recommendations you get on Spotify based on your listening history.
It is important to understand the difference between algorithm 1 and algorithm 2. Algorithm 2 is always a lot more complex than Algorithm 1. Algorithm 1 is always a fixed model that has a maximum of 5 parameters, while algorithm 2 can have millions. The algorithms BiOptSat can produce are relatively tiny, meaning hundreds of parameters, not millions.
You can also think about the complexity like this: imagine a world where even the most complicated algorithm would just be written as a simple quadratic equation: ax²+bx+c. In this instance, a training algorithm would be something that produces the most suitable values for a, b, and c. These values produce an algorithm that can be used in real-life applications.
Are you trying to tackle the black box problem in your work?
Normally, training algorithms have only one objective for the models they produce, which is accuracy. BiOptSat has two objectives: accuracy and interpretability (the objectives can also be changed, but these are the choices we are working with currently). Because BiOptSat uses two objectives, the models it produces are fairly transparent.
BiOptSat itself does not have to be transparent, and the reason is simple. Think about it this way: if you know for a fact that all the ingredients in a dish won’t hurt you, you don’t have to care about how it is cooked anymore — you know it is safe to eat because of the ingredients that are all safe to eat. In other words, it is not important how algorithm 2 is produced, because if it is transparent in the end, you can see everything relevant in the model itself.
For most commercial purposes, the lack of transparency is not a big problem, because all you want is good results. But in some cases, for example in the medical field, it is important to understand how the model is producing the results it is producing, for example for ethical and legal reasons. This is where bi-objective optimization can be useful.
What do you mean when you talk about interpretability in machine learning?
Simply put, interpretability tells you how easy the model is to understand for a human who uses it. It is difficult to find a way to measure interpretability. However, one proxy that is often used is the size of the model.
Let´s have an example to illustrate this. A decision tree is a kind of machine learning model BiOptSat can be trained to produce. When presented visually, they look something like this:
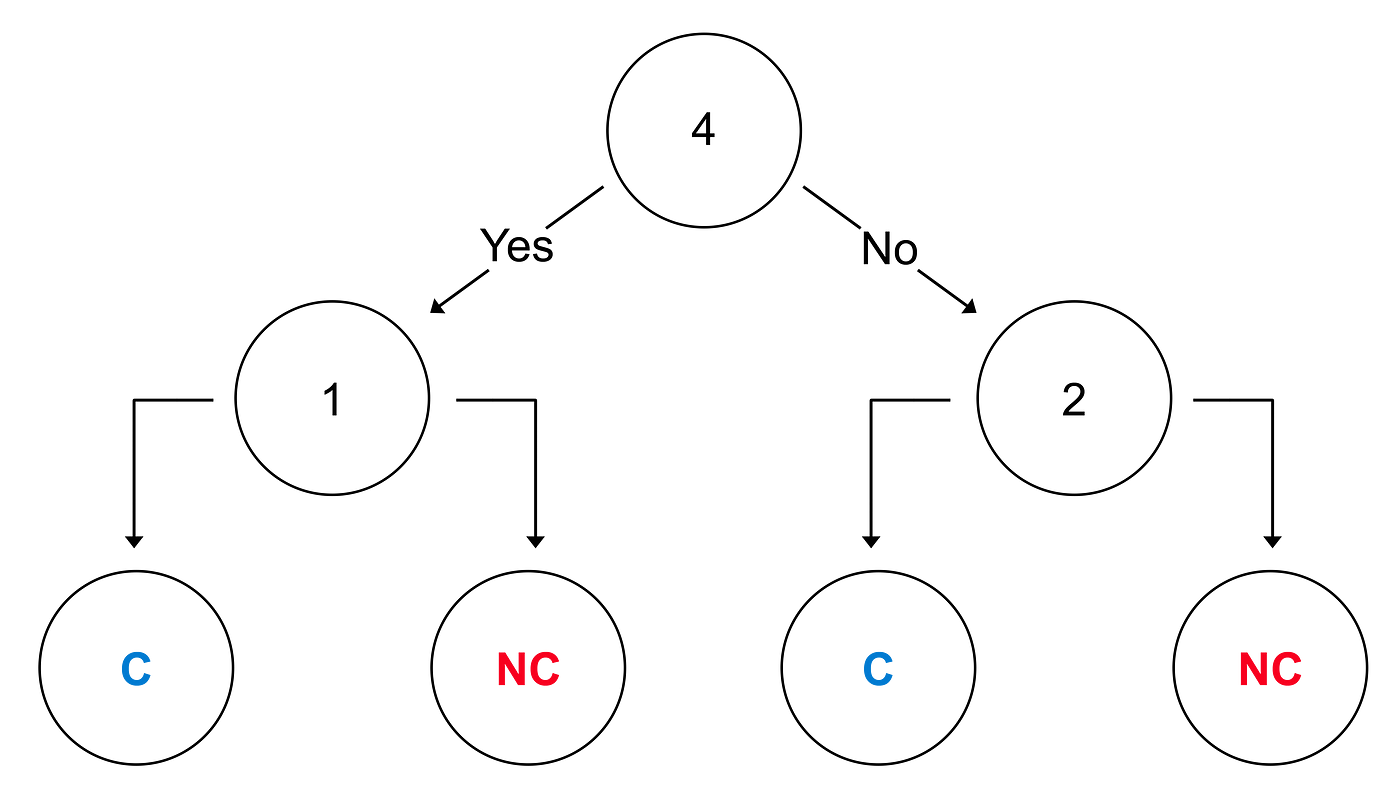
The top circle is called the root node and the bottom circles are called leaf nodes. The tree is the wrong way around from real life, which is a bit counterintuitive. But that is how they are drawn.
You may have an optimization problem such as a classification task: Is this picture of a cat or a bird? In this example decision tree, you start with node 4 and ask a question: Does it have four legs? Yes: go to node 1. No: go to node 2. And so on, until you are at a leaf node. The result can be for example “C — it is a cat”, or “NC — it is a bird”.
A machine learning model like the decision tree is interpretable (or understandable) by nature if it is small enough. But if the tree gets very big, it can get less understandable. Therefore, size is a decent proxy for understandability for this kind of algorithm, and pretty much the go-to interpretability proxy for all algorithms that are understandable by nature.
The number of rules and the length of the individual rules are ways to measure the size of a model. For decision trees, you can also measure the highest number of steps between the root node and a leaf node or the number of nodes.
To make the concept of a decision tree a little bit more tangible, here is an output example from BiOptSat:

Based on this, you can draw a visual representation of a decision tree (as shown below). In this picture the size of the decision tree is visible. It also shows how balanced the tree is. An unbalanced decision tree may be easier or harder to understand, depending on its exact structure.
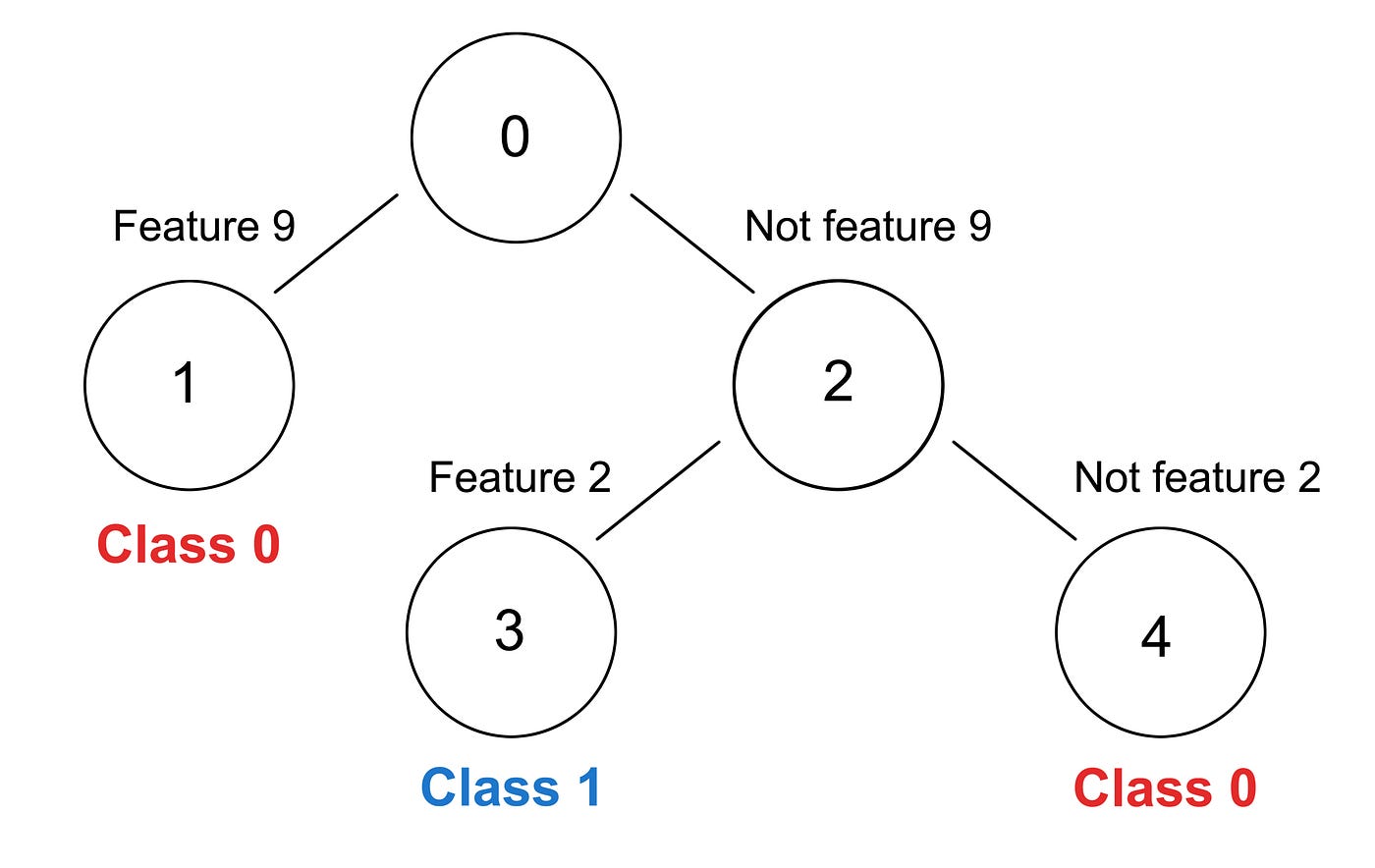
There are nodes 0 to 4 and the decisions are based on features marked with numbers. The first step could be “If feature 9 is true, go to the left, if it is false, go to the right”. These features can be just any kind of binary statements, something like “has four legs”. For the leaf nodes, you just have two classes (0 and 1), something like the cat or bird from the earlier example.
Would it be possible to make an algorithm for a commercial company dealing with a lot of consumer data that is interpretable?
Basically yes — but the algorithm will most likely give bad results. Currently, most of the algorithms on such applications are far from understandable. Usually, people try to interpret their operation afterward by looking at the results and trying to work out how the model got there based on them. However, I do not think this is the ultimate solution to the transparency problem. I think a machine learning model needs to be transparent by design. This is why we should develop interpretable models such as decision trees further.
There is a trade-off in machine learning stating that with high transparency, you lose the guarantee that there are no better results out there. This is because two objectives — accuracy and interpretability — are often in conflict with each other. If you want to make a decision tree model more accurate, it needs to be bigger, making it less understandable. And if you want to make it smaller and more understandable, it loses accuracy.
You can try to solve this problem by defining a desirable balance for your tradeoff. For example, you can say that both accuracy and interpretability are equally important. Reporting accuracy and size is doable for any model. BiOptSat goes one step further because it takes both objectives into account individually and produces several results illustrating how the two objectives conflict. This means that you do not have to determine the trade-off in advance.
Note that in machine learning, there can be interactiveness without interpretability. This means that you can have people interfere with the operation of a model without knowing what it does. On Spotify, for example, you could choose the option “I don´t like this song” to give feedback on a recommendation. This will affect the recommendations the algorithm gives, but it does not mean that the algorithm behind the recommendation is understandable to its user, or even to its creator.
Why is it useful to be able to analyze different trade-off options for your algorithm?
To answer this, let´s have a bit more practical example. We have established there are 2 objectives for our solution– accuracy and size. For an optimal solution, you cannot make one objective better without making the other objective worse. Let´s say you run BiOptSat on a set of training data and it gives you these results (note that in reality, there are far more options for the resulting models):
Model 1: accuracy 80%, size 50
Model 2: accuracy 80%, size 20
If your goal is to have high accuracy and small size, you choose model 2.
But what happens if we add a third option:
Model 3: accuracy 85%, size 35?
Now it is not possible to say directly, which is better, model 2 or 3, because while 2 is simpler, 3 is more accurate. The choice depends on the real-life application the resulting algorithm will be used for. Some applications could benefit from higher accuracy but lower interpretability, and vice versa.
In bi-objective optimization, you know about the trade-off for the accuracy and size of the model you are making. This means you can make more informed decisions as a human in charge of the development of a real-life application. The benefit of this is increased transparency and accountability in the whole process.
Earlier you said: “There´s only one goal for BiOptSat — for it to be fast.” Can you explain this a little further?
Any working exact algorithm will give you the same result — the best one. This is included in its definition of “exact”. Some other research groups do the same thing as we do, which means there are also other exact algorithms such as BiOptSat that use two objectives. The way to compete between these (and any algorithms) is speed and speed only.
BiOptSat should only be compared to other exact algorithms that can have two objectives with constraints formulated in Boolean logic. This means that the goal for our research group is to make BiOptSat the fastest algorithm in this category. We are not so much concerned with the results BiOptSat gives (as long as we know that they are correct), but with shortening the time it takes for the algorithm to give its results.
Describe the future development process of BiOptSat.
The problem with exact bi-objective algorithms is that they are usually not scalable to large chunks of data, which is also the challenge with BiOptSat. In our research, we are striving to eventually overcome that challenge. To make it more scalable in the future, we need to focus on the Boolean formula the algorithm is working on. The make the algorithm faster, the formula needs to be reduced to a simpler, shorter form than it initially was. Hopefully, the simplified problem will run faster in the training algorithm. This process of reducing the formula is called preprocessing.
Here is a simple example of the reduction process: Let us say there is a problem: “(a or b) and (not b or c)”. This is actually the same as “a or c” and can therefore be reduced to that form (provided that “b” is not important for the problem and can be written out).
We have a preprocessing algorithm that does this simplification for the training algorithm to use. The preprocessing algorithm also takes time to run and be tested. We hope that it will eventually shorten the time BiOptSat takes to run enough so that it makes the whole preprocessing worthwhile. But this is research, meaning that there is no guarantee that this will be the case.
Why did you get into research?
Since I was a child, I have wanted to know the background of stuff — I wanted to truly understand how something works. At the bachelor level of my studies, I was often told what to do, but not why the techniques we used worked. I went into a more theoretical direction after that. To find out whether I wanted to do a Ph.D. I started as an intern in the research group I currently am in. I know now that I want to continue my research work with a Ph.D.
Nowadays my work is more theoretical than practical. Our research group does a little bit of the tailoring of tools for real-life applications, but our research is mainly about creating technology for future applications. This means that things we develop, such as BiOptSat, do not have any real-life applications yet.
Tell me more about your research philosophy.
To me, research is all about thinking outside of the box. I like the work because of its flexibility. I can just come up with stuff, see if it works, and then repeat it if it does not.
In any field of science, there are always people who are interested in basic research and people who are interested in applied research. For example, in biology, some researchers just want to know how a molecule is compiled for its own sake. Others are interested in where to use that knowledge for real-life applications. I think a case can be made for both, but I have always belonged to the former kind.
In computer science, there is no nature to look at, but it is more about how to improve the things one creates. In a sense, it is about pushing the mind’s ability to solve complex problems further and further by finding ways to make algorithms faster and faster. Even if some part of the algorithm creation process is automated, human beings need to come up with the automation in the first place, as well as with ways to improve it (training algorithms, preprocessing, etc.). I like the mental challenge basic research provides.
For my upcoming Ph.D., I will continue research on multi-objective optimization. One application of that is fairness in machine learning.
To illustrate fairness, let´s think of a model that looks at a dataset with men and women. As usual, the model has accuracy as the other objective. If you have fairness as the other objective, you can look at how accurate the results are for men, and how accurate the results are for women. If there is high accuracy for men, and low for women, the fairness of the model is low. If the accuracy levels are virtually the same between the sexes, the fairness is very high. A numeral value for fairness could be for example the absolute difference between the accuracy levels of men and women.
What does AI mean to you?
As a term, artificial intelligence is complicated. What even is intelligence? I think AI is often associated with a kind of intelligence that is quite far from the reality of AI right now.
Often when talking about AI people actually mean AGI, artificial general intelligence. This type of AI is often seen in fiction, too. Right now, the things AI can do fit a very narrow definition of intelligence, if that.
I find the term AI so overused it does not mean anything anymore. Among computer scientists, we joke about people trying to sell simple “if x, then y” commands as AI. A modern decision tree is not that much complicated from a single command like that. Modern machine learning is essentially creating a decision tree automatically, instead of writing it by hand. In other words, it is not a human being writing the algorithm; it is a human being writing the algorithm that writes the algorithm. But humans are still needed as the initiator of the whole process.
Machine learning is essentially boiling huge datasets down to patterns. In classification, you need classes when you input data to teach an algorithm. You may have images of dogs and cats for learning, and you need a label for each image — is it a dog or a cat? The machine learning model will learn from pictures with labels, and then later predict the label of an image from the image alone. After training, computers are way more effective at pattern recognition than humans in huge datasets.
Image recognition is pretty good right now, but some weird errors are still happening. This is because, in images, the computer sees only ones and zeros. From a chain of numbers, it finds patterns. Still, it can make mistakes looking at images that humans would not do. Medical data on the other hand is usually already in numbers — here, humans are easily overwhelmed. A computer is way better at finding patterns from this kind of data than humans. This is why algorithms can work astonishingly well in tasks such as going through medical records and finding early signs of cancer.
Author´s note 2:
If you made it this far, I want to thank you for your patience. Now that we are at the end of this article, I want to include one more question. It is not because it is a particularly good one; it is quite the opposite. I want to present it because I believe it will demonstrate just how difficult it can be to try to grasp this article’s concepts.
Mind you, I asked this question after having talked to Christoph about his work for hours. I still got my ideas surrounding it quite wrong. Luckily, he was patient enough to correct me in a friendly way. I feel like cross-disciplinary conversations like these are what humanity needs to truly evolve.
Go ahead and ask the wrong questions — you will get the right answers.
In your own words, what is the difference between machine learning and other types of optimization? I tried googling it but the answers are a bit complicated…
That’s probably not quite the right question to ask. It is more that there are tasks within machine learning that require optimization but at the same time, optimization can also be required in completely different applications. It’s more like an optimization algorithm is a tool, like a mixer. You might need a mixer for cooking, baking, or construction. But it’s not the right question to ask what the difference between a mixer and baking is.

Written by Tuula Cox. This article was also published on Medium. I am happy to answer any inquiries relating to this article through my LinkedIn.